
I’ve talked to a fair number of teachers who find it easier to use twitter than to blog to share their classroom learning. I’ve been thinking a little of how to make that easier but got side tracked wondering how schools, teachers and classes use twitter.
If you use twitter on the web it tells you the application used to post the tweet. At the bottom of a tweet there is the date and the app that posted the tweet.
I’ve got a list that is made up of North Lanarkshire schools I started when I was supporting ICT in the authority.
I could go down the list and count the methods but I though there might be a better way. I recalled having a played with the twitter api a wee bit so searched for and found: GET lists/statuses — Twitter Developers. I was hoping ther was some sort of console to use, but could not find one, a wee bit more searching found how to authenticate to the api using a token and how to generate that token. Using bearer tokens
It then didn’t take too long to work out how to pull in a pile of status updates from the list using the terminal:
curl --location --request GET 'https://api.twitter.com/1.1/lists/statuses.json?list_id=229235515&count=200&max_id=1225829860699930600' --header 'Authorization: Bearer BearerTokenGoesHere'
This gave me a pile of tweets in json format. I had a vague recollection that google sheets could parse json so gave that a go. I had to upload the json somewhere I could import it into a sheet. This felt somewhat clunky. I did see some indications that I could use a script to grab the json in sheets, but though it might be simpler to do it all on my mac. More searching, but I fairly quickly came up with this:
curl --location --request GET 'https://api.twitter.com/1.1/lists/statuses.json?list_id=229235515&count=200&' --header 'Authorization: Bearer BearerTokenGoesHere' | jq '.[].source' | sed -e 's/<[^>]*>//g' | sort -bnr | uniq -c | sort -bnr
This does the following:
- download the status in json format
- passes it to the jq application (which I had installed in the past) which pulls out a list of the sources.
- It is then passed to sed which strips the html tags leaving the text. (I just search for this, I have no idea how works)
- next the list is sorted
- then uniq pulls out the uniq entries and counts then
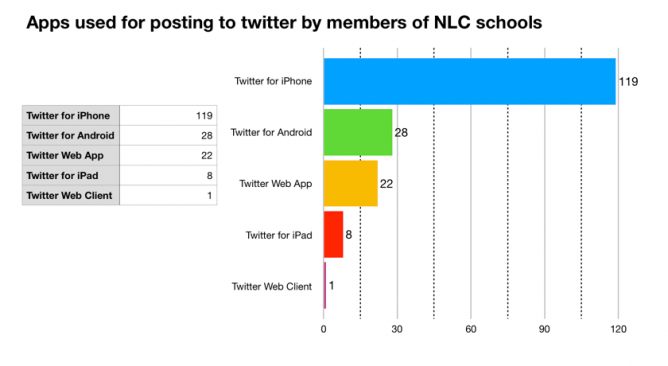
- Finally sorts the counts and gave:
119 "Twitter for iPhone" 28 "Twitter for Android" 22 "Twitter Web App" 8 "Twitter for iPad" 1 "Twitter Web Client"
This surprised me. I use my school iPad to post to twitter and sort of expected iPads to be highest or at least higher.
It maybe that the results are skewed by the Monday, Tuesday holiday and 2 inservice days, so I’ll run this a few times next week and see. You can also use a max_id parameter so I could gather more than 200 (less retweeted content) tweets.
This does give me the idea that it might be worth explaining how to make posting to Glow Blogs simpler using a phone.
Update, Friday, bacn to school and NLC looks like:
74 "Twitter for iPhone" 51 "Twitter for iPad" 18 "Twitter for Android" 10 "Twitter Web App" 1 "dlvr.it"
Mentions