I ve just added https://mastodon.social/@johnjohnston to my rel=me links on the sidebar on my blog & on my twitter profile. I joined mastodon in 2016 but have never been very active. A bit more so over the last summer.

I ve just added https://mastodon.social/@johnjohnston to my rel=me links on the sidebar on my blog & on my twitter profile. I joined mastodon in 2016 but have never been very active. A bit more so over the last summer.
We’re on the eve of the Elon Musk / Twitter deal closing. In his Dear Twitter Advertisers letter, Elon writes: The reason I acquired Twitter is because it is important to the future of civilization to have a common digital town square, where a wide range of beliefs can be debated in a healthy mann...
The common digital “square” should be the entire web, with a diverse set of platforms. There should be common APIs but many communities with their own rules, goals, and business models. Concentrating too much power in only a couple social media companies is what created the mess we’re in. The way out is more platforms, free to make the best decisions for their users knowing that there are options to leave and less lock-in for developers.
Manton always seems to hit the nail on the head.
A tiny thought on the current uk news. It worries me they way politicians use Twitter to post letters of resignation & the like. Trusting Twitter with something so important seems like a mistake. Surly they should post somewhere they control & forward to Twitter #indieweb
A quick test to see if ticking the syndicate to mastadon via the Syndication Links plugin works. Like a lot of others I am poking around mastadon again. I think my preference is still POSSE from my own site for social. I didn’t like the way twitter has become the official comms for schools & government before last week.
The microblogging book by @mantonsblog is full of both technical and ethical info:
https://book.micro.blog
http://micro.blog is IMO a great model of smallish communities & solving a lot of social problems. It syndicates hosted & external sites.
Over the years I’ve often though that video is most useful as a tool for pupils to report on their learning and learn a little about making media. I have not changed my mind but recently I’ve found myself using it to share learning quickly myself quite often.
There are a couple of useful Apps I’ve been using to do this, both have, in my opinion advantages over iMovie and clips.
HyperLapse is one I’ve used for years now. It seems to be called ‘Hyperlapse from Instagram’ now. It is however free and can be used without having an instagram account. Its main purpose is to record speeded up videos. But the main feature I use it for is it smooths out hand held video with automatic stabilisation. This means you quickly move through the classroom videoing activity and get a fairly good result without editing.
Here is an example I posted to twitter today:
A lot of talking and listening going on the in Biggies this afternoon. #stem #creativity @MrDormanSTEM pic.twitter.com/P70AvSG63k
— Banton Primary (@Banton_Pr) November 8, 2021
Snapthread is another handy choice. It quickly pulls together videos from ‘live photos’ on iOS. You can add music, titles and the like quickly. I’ve found it especially handy in impressing visitors who ask me to tweet photos of their work with my class. I can usually get a video up in just a few minutes. You just need to try and hold the camera still for a moment or two before of after clicking the button. 30 second videos free, but I was delighted to be able to pay for longer ones to support an independent developer.
Here is a Snapthread example:
The Biggies had a bit of fun this morning with a tables challenge and tarsia puzzles for #mathsweekscotland pic.twitter.com/f0Iho5PqfR
— Banton Primary (@Banton_Pr) September 29, 2021
I’d not claim any artistry or skill in making these videos but they only took a couple of minutes to create. The longest part was probably the upload to twitter.
I also upload these to our class blog. I’d much rather just use the blog but twitter is ubiquitous in Scottish education now:(
If you ever need an injection of positiveness, try this Twitter trick that'll show tweets with the word "love" from people you follow.
Well this is clever
lovely idea
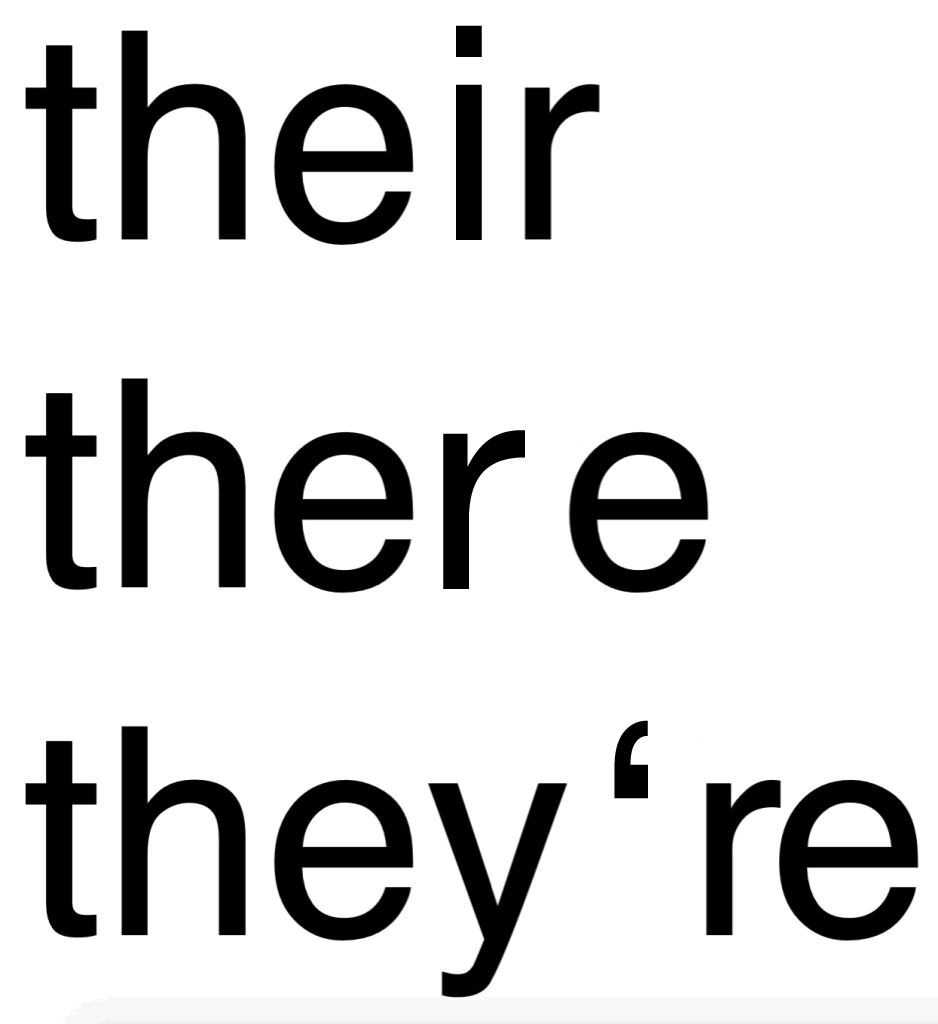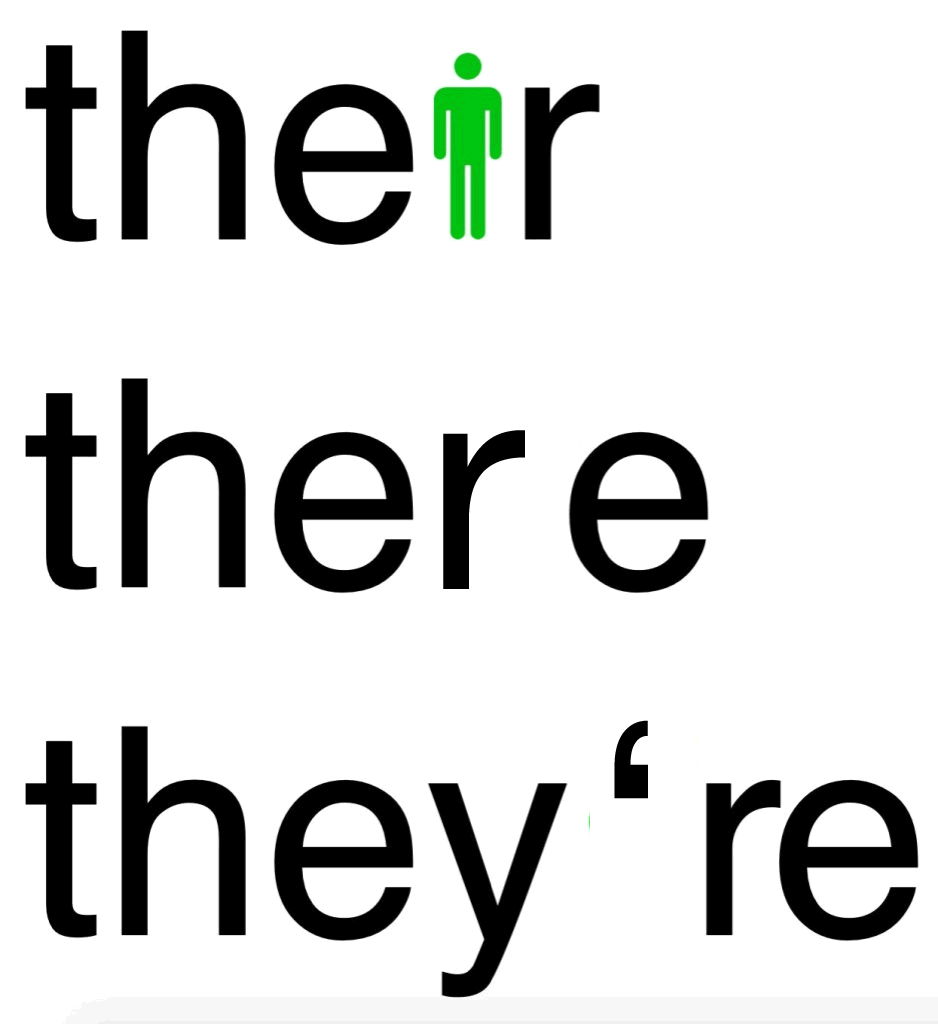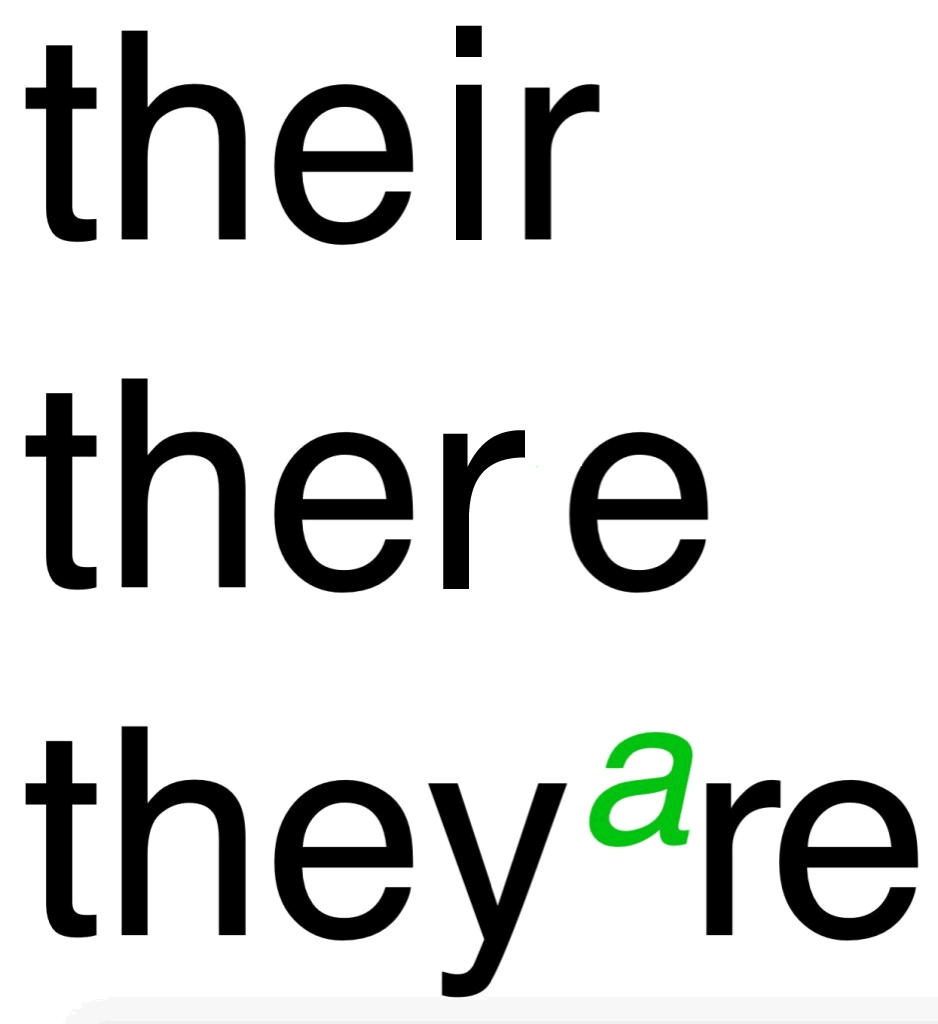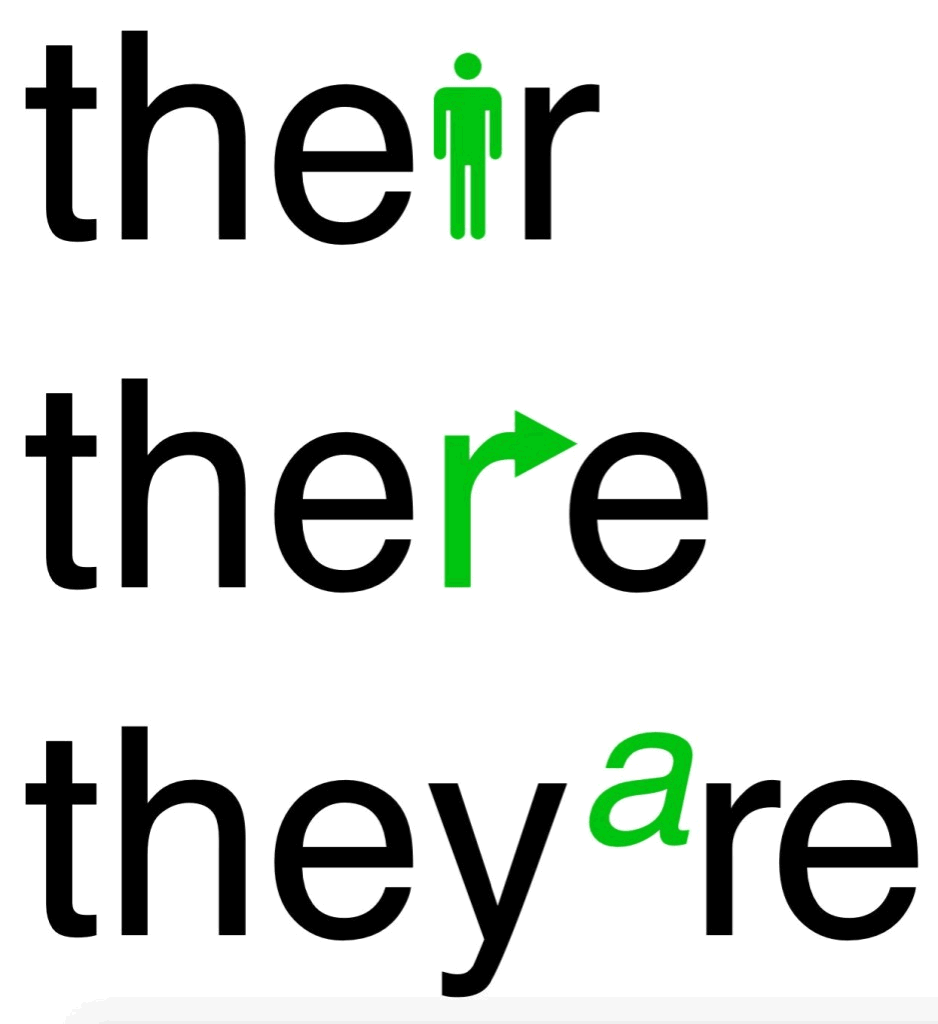
1. Reading your & other blogs.
2. Resources, Twitter is good for easy short term sharing not for long term discovery.
3. Time
Posting this via my blog, where it belongs and is organised by me in my online memory.
Along with avoiding @ewanmcintosh’s “keynote-speaker-sponsor-driven” & keeping to
@magsamond’s “non-hierarchical, open, peer-to-peer” I think early #teachmeet principals of everyone being willing to participate & serendipity of random were interesting ways to change dynamics.