Pinboard
I’ve been using pinboard for collecting links for five years now. I like it a lot, it feeds the Links page here and most of the enviable stuff.
One of the main things I like about it is its simplicity. Pinboard lists the links, titles, and descriptions without any images or fancy stuff. Adding links via the bookmarklet is simple. It supports the delicious API and has RSS so you can pull sets of links onto blogs and webpages easily enough.
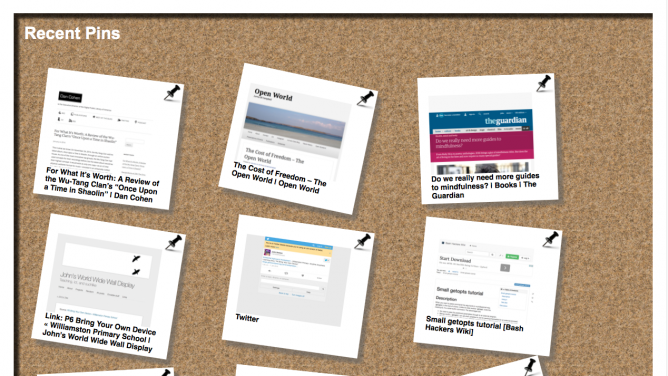
Last week I used the service to play around with python a little. To produce a more visual representation of my recent links. I appreciate the irony. This was an excuse to play with several technologies that I do not know much about.
Last month I had read: this post Homemade RSS aggregator followup by Dr Drang. This shows how to make an RSS reader with python.
I’ve very occasionally played with python for an hour or two but do not really understand the basics. I can however try things repeatedly until they worked.
Planing and playing
My plan was to use the code from Dr Drang, simplifying it to deal with just one RSS feed. Using my pinboard links to produce a webpage. I also wanted to make thumbnails of the websites linked and play with CSS and JavaScript a bit.
The idea was to create the webpage in my dropbox. This could be updated automatically by the script running on my mac. I’ve had dropbox long enough to have a Public folder that is very handy for publishing webpages. This is now a pro and business option only.
Here is the script: pinboardrecent.py and the current output: Recent Pinboard.
Problems
The interesting thing about all of this is the several problems I hit and their solution.
The problem included:
- Not know how to do something
- Errors in the code I wrote
- Errors with webkit2png 1 which I was using to produce the thumbnails.
The answers all involved google and testing and re-testing until things worked. In some all cases I am sure my answers were not the best way of doing things but they worked. I’ve noted most of these in the source. The other think I see in my code is lots of print statements that are commented out. I deleted lots more. There are surely better ways to find out what is going on/going wrong with a script but this works for me.
I am never going to be a programmer, but I get a lot of fun and occasional utility out of playing around like this.
There is a huge push to teach coding to pupils in school going on at the moment. A major reason for this is getting the right skills for employment. I hope a small side benefit will be giving learners the chance to have fun. Producing things for themselves rather than just use services and applications produced for them.
Tinkering with code that you do not understand may not be the best way to get a deep understanding of a language. It may not even help with learning the fundamental concepts. It does in my experience hook you into engaging with learning.
This term at work I’ll be involved in providing training in starting primary pupils coding. I’ll be recommending tinkering as one possible way of getting started and engaing pupils. I am sure some will be as fascinated as me.
- webkit2png has problems when trying to get thumbnails of non https sites on El Capitan (Mac OS X 10.11) google allowed me to find a fix and edit the source of webkit2png (which turned out to be python for extra learning). ↩