
Might be good #digitalliteracy to talk about video size? I remember back when I started kids posting online 1st lesson was resizing jpgs to 480 pixels. Unfortunately more modern tech makes this less easy. In class we do an Airdrop back & forth so I can squash videos for kids.
Tag: Digital literacy
Brilliant digital literacy lesson Idle Words: Anatomy of a Moral Panic via @adactio
Adactio: Journal—In AMP we trust
Google says it can’t trust our self-hosted AMP pages enough to pre-render them. But they ask for a lot of trust from us. We’re supposed to trust Google to cache and host copies of our pages. We’re supposed to trust Google to provide some mechanism to users to get at the original canonical URL. I’d like to see trust work both ways.
Source: Adactio: Journal—In AMP we trust
Reading above my pay grade again.
More about Google’s AMP stuff here: Google AMP is good for mobile web users – but what about publishers? | Media | The Guardian
One of the things it does is present your content quickly without all the javascript that slows pages down, but it also seems to hijack the ULR and give the material a google one.
Given Schools should teach pupils how to spot ‘fake news’ – BBC News, it might make understanding and evaluating content even harder.
A Facebook Like
Facebook was the key to the entire campaign, Wigmore explained. A Facebook ‘like’, he said, was their most “potent weapon”. “Because using artificial intelligence, as we did, tells you all sorts of things about that individual and how to convince them with what sort of advert. And you knew there would also be other people in their network who liked what they liked, so you could spread. And then you follow them. The computer never stops learning and it never stops monitoring.”
from: Robert Mercer: the big data billionaire waging war on mainstream media | Politics | The Guardian
Carole Cadwalladr’s article in today’s Observer, is both fascinating and frightening. The technology used by Cambridge Analytics is incredibly powerful the use it has ben put too worrying. Andy Wigmore, Leave.EU’s comms director in the quote above doesn’t have a Facebook account quoted in the same article:
It is creepy! It’s really creepy! It’s why I’m not on Facebook! I tried it on myself to see what information it had on me and I was like, ‘Oh my God!’ What’s scary is that my kids had put things on Instagram and it picked that up. It knew where my kids went to school.
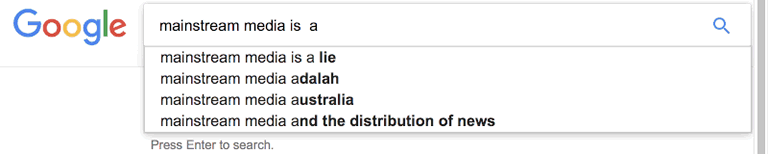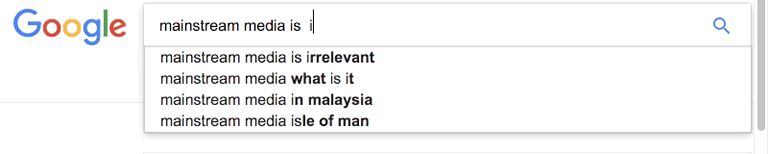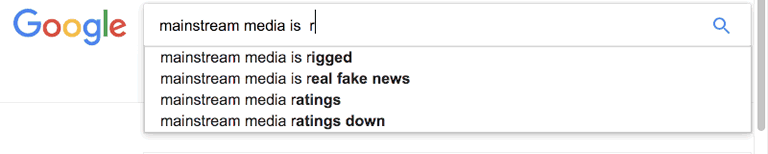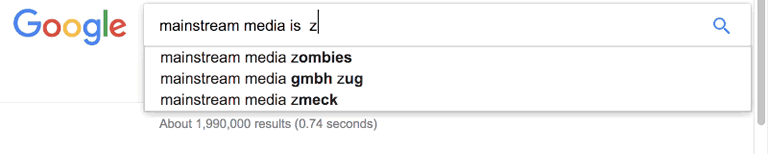
Featured image on this post created with a wee AppleScript Makes auto complete google search gifs.
Reverse Digital Literacy

A few years ago I posed about an interesting use of Google reverse image search:
And over the years I’ve read a good few posts about the tool on Alan’s blog (e.g. The Hidden Complexity of Attribution, Reverse Image Search ).
This week I’ve been reading more fascinating uses of the tool: Cleanup Time and Road Trip
I am even more strongly minded that we should be starting to teach these skills from a young age. How easy that will be I don’t know.
A few weeks ago, during the scary clown storm I was hearing about clown stories every day. One pupil was most insistent that there was a clown plague. The pupil presented me with ‘evidence’ from his iPad. This was a photo of a dead clown stretched out shot on a New York street. I took a look with the idea of demonstrating a wee bit of fact checking. On scrolling down below the picture I found the headline explaining that this was a fake photo! No detective work needed.
I am not quite sure where to start with this teaching. Perhaps using the reverse image search to identify things or creatures combined with some work on The Pacific Northwest Tree Octopus.
The problem is that the fake stuff is catchy, fun and enables us to grab a quick stance.
Featured image Reversed | Pekka Nikrus | Flickr BY-NC-SA
Digital Curiosity
maybe, in concert with an emphasis on making and collaborating and bug reporting and embracing other values of the open web, individuals can help reorient the cultural attitude toward technology away from entanglement and back to a place of enlightenment.
The Age of Entanglement – The Atlantic
Interesting Article. More grist for the ‘why we need to teach digital literacy and curiosity’ mill via @livedtime
Featured image Qsquare quantum pseudo-telepathy from flickr
Creative Commons — Attribution 2.0 Generic — CC BY 2.0